A quick word from me
This issue isn't sponsored - I write these deep dives in my free time and keep them free for everyone. If your company sells AI tools, dev tools, courses, or services that .NET developers would actually use, sponsoring an issue is the most direct way to reach them.
Want to reach thousands of .NET developers? Sponsor TheCodeMan →The Problem
It's very common for CRUD operations and REST APIs to use primary keys to reference data that will be accessed or modified. These keys are often implemented as surrogate keys using sequential Integer values. A typical API route looks like this: GET /api/v1/user/:id GET/api/v1/user/12 In this case, Id:12 represents a unique (sequential) identifier for a specific user record in the database. In general, this is the simplest and most effective way of specifying the data/record to retrieve.
The question is, what is the problem with this approach?
The main problem is that it exposes our API to security risks because we are displaying the raw identifiers to the user, especially sequential ones. By exposing these primary keys, we give users the ability to estimate the number of records in our tables and easily guess the values of other records. Suppose authorization isn't implemented effectively in our code, or APIs aren't protected. In that case, the users could input the next number in the sequence (for example, number 13) to access information they otherwise shouldn't have.
What about GUID identifiers?
There are some positive aspects of GUID values:
- They are globally unique, across every table, every database, and every server.
- They enable the easy merging of records from different databases.
- GUID IDs can be Generated anywhere instead of having to roundtrip to the database.
However, there are many non-intuitive but critical downsides to the use of GUID values for primary keys in a database. The main reason is performance as well as unnecessarily excessive use of server resources within the database:
"A GUID as the clustering key isn't optimal, since due to its randomness, it will lead to massive page and index fragmentation and to generally bad performance."
- Kimberly Tripp - the Queen of Indexing A GUID is more than 4 times larger than the traditional 4-byte index value; this can have severe performance and storage implications if we aren't careful. Here are some quick calculations for using Integer vs. GUID values in a table of 1,000,000 records: As Primary Keys:
Integer values use 3.8MB vs. 15.26MB for GUID values. As Clustering Keys: With 6 non-clustered indexes, Integer values use 22.89MB vs. 91.55MB for GUID values. TOTAL: 25 MB (Integer) vs. 106 MB (GUID) for the single table. Calculation borrowed from the Kimberly Tripp blog.
The Solution
We have seen that both types of identifiers (sequential Integer & GUIDs) have their respective risks/problems. So, can we use the "pros" of both types without their adverse risks? Yes, we can. One solution is to use Hashids (Hash ID Values) …Hashids are an effective approach for generating opaque non-sequential IDs derived from numbers/sequential IDs (e.g., Integer) and hashing algorithms; converting numbers like 347 into an opaque strings identifier such as "ir8". Let's expand on the example from above. We need to access the data of users with ID 12, but we do not want to display the sequential ID through the API, to minimize security risks...
[HttpGet]public IActionResult Get([FromRoute] string id){ int[] intId = _hashids.Decode(id); if (intId.Length == 0) return NotFound(); User user = _userService.GetUser(intId[0]); if (user is null) return NotFound(); return Ok(user);}The API method above accepts an argument ID of type string. The Hashids library provides a ready-to-use implementation with a Decode function that converts a string identifier back to its original sequential ID/number, derived from the Encode function. We can now efficiently retrieve the record from our data warehouse where the data is still stored using its' original sequential identifier. Suppose our dataset is a list of users from the database, represented by the following list structure in C#:
private List<User> Users = new List<User>{new User { Id = 1, FullName = "Stefan Djokic" },new User { Id = 2, FullName = "Ricky Sellers"},new User { Id = 3, FullName = "Tasnim Shaffer"}};If we call the example API above in Postman with a hashid (string ID) of "W8ZwkZY" (derived from Id:1 in this case), the result is the user with ID = 1. To recap, this is because the Hashid derives from, and can be converted back to, its original sequential identifier.
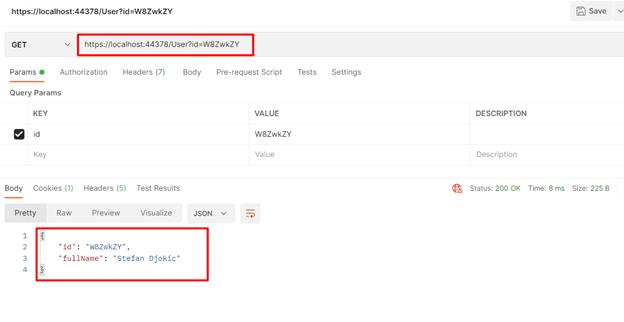
This has enabled us to simultaneously take advantage of the best features of Sequential IDs and GUIDs. We've minimized our security risk by exposing opaque identifiers to the public (which cannot be easily guessed due to the hashing algorithm) while maintaining performance when storing and searching in the database.
How does it work?
Remember integers to hex conversions? Hex numbers use the alphabet as a base-sixteen numeral system. Hashids use the same principle of conversion; however, the alphabet is base62. In addition, the alphabet is shuffled based on a unique salt value that can be set by the user. This makes each implementation algorithm unique and is how our security risks are mitigated.
What about performance?
As far as performance is concerned, the general best practice is that these IDs should not be persisted anywhere but should be calculated every time. One of the main reasons for this is that it enables us to change/rotate the SALT key.
Therefore, most uses of Hashids will require the calculation to be done two times for each request; one calculation is encoding (int is converted to string), and the other is decoding (string is converted back to int).
The encoding and decoding execution times (for a 7 characters id) are shown in the following figure (using the venerable BenchmarkDotNet project).
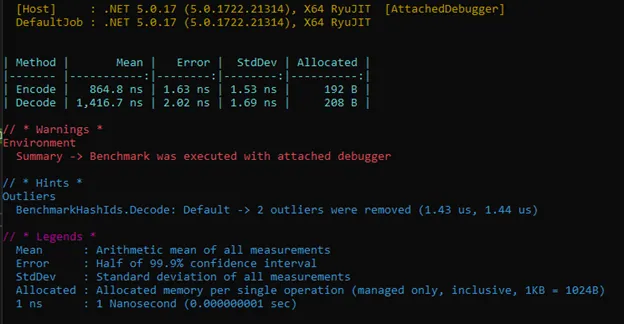 We can see that the encoding function takes approximately 850ns per execution, which is quite fast. The decoding time is a bit longer (not unexpected), taking approximately 1400ns (i.e., 0.0014ms).
Note: Functions do not return a single value of a particular type, but return a string - encoding returns int []. There is a lot of room for optimization here if someone really needs it.
Another note: Purely out of curiosity, I tested on 1 million values, although this is far from a realistic or practical use case, and the total duration of the process was slightly less than 900ms.
We can see that the encoding function takes approximately 850ns per execution, which is quite fast. The decoding time is a bit longer (not unexpected), taking approximately 1400ns (i.e., 0.0014ms).
Note: Functions do not return a single value of a particular type, but return a string - encoding returns int []. There is a lot of room for optimization here if someone really needs it.
Another note: Purely out of curiosity, I tested on 1 million values, although this is far from a realistic or practical use case, and the total duration of the process was slightly less than 900ms.
Wrapping up
Hashids are an effective approach for small to medium-scale applications that don't require more complicated strategies like Snowflake IDs (e.g., combining different metadata such as timestamps, shard IDs, etc.). And many industry solutions such as GraphQL have embraced it due to the benefits outlined here. Fun fact: YouTube uses 11 characters to generate an ID for each of the videos. This number of characters allows the existence of 73,786,976,293,838,206,464 video clips, which is equivalent to every human being on the planet uploading video every minute for the next 18,000 years. Just WOW. Github repository of the entire code: HashIDs (The repo is from last year - created in .NET 5 - but everything is the same). HashIds library used in the text is hashids.ne. That's all from me today.





