Sponsored
- Boost your C# / .NET development with the best combination of visual ORM builder and ADO.NET data providers. Download a 30-day free trial today and enjoy reliable updates, expert developer support, and full compatibility with leading ORMs. Get 15% OFF with promo code DOKIC15. Check it now
- I'm preapring Enforcing Code Style course in my TheCodeMan Community. For 3 consecutive subscriptions ($12) or annual ($40) you get this course, plus everything else in the group.🚀 Join now and grab my first ebook for free.
Many thanks to the sponsors who make it possible for this newsletter to be free for readers.
Want to reach thousands of .NET developers? Sponsor TheCodeMan →
What is RAG?
RAG (Retrieval-Augmented Generation) is an AI framework that enhances generative large language models (LLMs) by integrating traditional information retrieval methods, such as search engines and databases. This approach allows LLMs to generate responses that are more accurate, current, and contextually relevant by leveraging both your data and broader world knowledge.
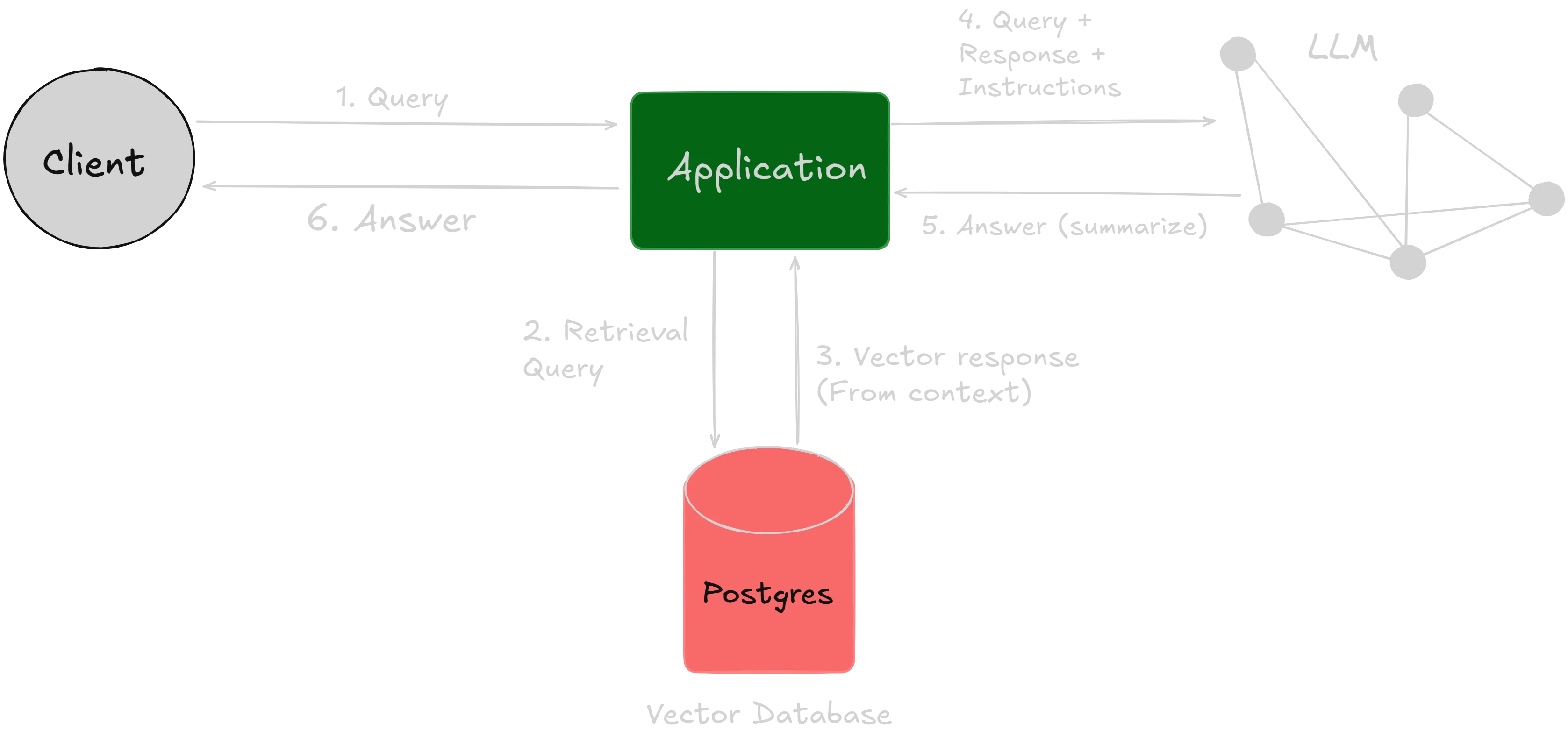
How does Retrieval-Augmented Generation work?
RAG systems work in a couple of key steps to make AI-generated responses more accurate and useful: Finding and Preparing Information: Instead of relying only on what an AI model already knows, RAG searches internal sources - like web pages, databases, or company knowledge bases, or anything that we give it - to find relevant information. Once it pulls the data, it cleans it up by breaking it into tokens, removing unnecessary words, and making it easier for the AI to process. Generating Smarter Responses: The AI then blends this fresh information with what it already knows, creating responses that are not just more accurate but also more relevant and engaging. This way, instead of guessing or relying on outdated knowledge, the AI can deliver answers that are both well-informed and up-to-date.
Example: Customer Support Chatbot with RAG
Imagine a company wants to provide instant and accurate answers to customer queries about its products and services. Instead of relying solely on a pre-trained LLM, which may not have the latest company-specific information, the chatbot is designed as a RAG system.
How It Works:
1. User Query: A customer asks, "What is the return policy for my latest order?"
2. Retrieval Phase: The system first searches the company’s internal documentation, knowledge base, or database (e.g., FAQs, policy documents, order history).
3. Augmented Generation: The retrieved information is then fed into the LLM, which generates a well-structured, context-aware response.
4. Response to User: The chatbot replies, "Our return policy allows you to return items within 30 days of purchase. Since your order was placed 15 days ago, you can still request a return. Would you like to start the process?"
By using RAG, the chatbot ensures its responses are:
- Accurate (based on the latest return policy)
- Up-to-date (fetches real-time order details)
- Relevant (answers specific to the customer’s situation)
How to implement it in .NET?
What I'm going to create:
I will use my brand TheCodeMan for these purposes, and I will create a mini-database that tells a little more about my brand, what I do, where TheCodeMan can be seen, a little about sponsorships and partnerships, and the like.
When I fill my database I will test the system through a couple of questions, to find out if the system knows some information about the brand itself based on the data of who has it.
Here I expect to get an answer like "I don't have such information" if I ask a question for which the answer is not actually in the database.
Let's implement it.
If you want to start with AI Basics in .NET, you can read How to implement Semantic Search in .NET.
Create Embedding Generator
The OllamaEmbeddingGenerator generates vector embeddings for textual data by interacting with the Ollama API.
It converts input text into a numerical representation (float[]), making it useful for semantic search, Retrieval-Augmented Generation (RAG) systems, and AI-driven applications.
The class sends an HTTP request to Ollama’s /api/embeddings endpoint, retrieves the embedding, and processes the response. If the API request fails or returns invalid data, it throws an exception to ensure reliability.
This embedding generator is essential for applications that require text similarity comparison, knowledge retrieval, and intelligent search. By using embeddings instead of traditional keyword matching, it enables context-aware search and AI-powered content recommendations.
When integrated with pgvector (PostgreSQL) or other vector databases, it allows for efficient semantic retrieval of relevant data based on meaning rather than exact words.
public class OllamaEmbeddingGenerator(Uri ollamaUrl, string modelId = "mistral") : IEmbeddingGenerator{ private readonly HttpClient _httpClient = new(); private readonly Uri _ollamaUrl = ollamaUrl; private readonly string _modelId = modelId; public async Task<float[]> GenerateEmbeddingAsync(string text) { var requestBody = new { model = _modelId, prompt = text }; var response = await _httpClient.PostAsync( new Uri(_ollamaUrl, "/api/embeddings"), new StringContent(JsonSerializer.Serialize(requestBody), Encoding.UTF8, "application/json")); if (!response.IsSuccessStatusCode) { throw new Exception($"Ollama API error: {await response.Content.ReadAsStringAsync()}"); } var responseJson = await response.Content.ReadAsStringAsync(); Console.WriteLine("Ollama Response: " + responseJson); var serializationOptions = new JsonSerializerOptions { PropertyNameCaseInsensitive = true }; var embeddingResponse = JsonSerializer.Deserialize<OllamaEmbeddingResponse>(responseJson, serializationOptions); if (embeddingResponse?.Embedding == null || embeddingResponse.Embedding.Length == 0) { throw new Exception("Failed to generate embedding."); } return embeddingResponse.Embedding; }}
IEmbeddingGenerator interface:
public interface IEmbeddingGenerator{ Task<float[]> GenerateEmbeddingAsync(string text);}
OllamaEmbeddingResponse:
public class OllamaEmbeddingResponse{ [JsonPropertyName("embedding")] public float[] Embedding { get; set; } = [];}
Create Vector Database with Neon
The TextRepository class is a data access layer that manages text storage and retrieval using Neon, a serverless PostgreSQL database. I created this database in less than 30s with a couple of clicks.
It works by storing text with vector embeddings and later retrieving the most relevant texts based on similarity. The repository relies on pgvector, a PostgreSQL extension for vector-based search, enabling efficient semantic retrieval instead of traditional keyword matching.
When storing text, it first generates an embedding using IEmbeddingGenerator (e.g., Ollama's embedding API) and then saves both the text and its embedding in the database.
When retrieving data, it converts the query into an embedding and finds the top 5 most relevant matches using a vector similarity search.
This setup allows fast and scalable AI-powered search, leveraging Neon’s serverless PostgreSQL, which was set up in less than 30 seconds, ensuring high availability and automatic scaling without database management overhead.
public class TextRepository(string connectionString, IEmbeddingGenerator embeddingGenerator){ private readonly string _connectionString = connectionString; private readonly IEmbeddingGenerator _embeddingGenerator = embeddingGenerator; public async Task StoreTextAsync(string content) { var embedding = await _embeddingGenerator.GenerateEmbeddingAsync(content); using var conn = new NpgsqlConnection(_connectionString); await conn.OpenAsync(); string query = "INSERT INTO text_contexts (content, embedding) VALUES (@content, @embedding)"; using var cmd = new NpgsqlCommand(query, conn); cmd.Parameters.AddWithValue("content", content); cmd.Parameters.AddWithValue("embedding", embedding); await cmd.ExecuteNonQueryAsync(); } public async Task<List<string>> RetrieveRelevantText(string query) { var queryEmbedding = await _embeddingGenerator.GenerateEmbeddingAsync(query); using var conn = new NpgsqlConnection(_connectionString); await conn.OpenAsync(); string querySql = @" SELECT content FROM text_contexts WHERE embedding <-> CAST(@queryEmbedding AS vector) > 0.7 ORDER BY embedding <-> CAST(@queryEmbedding AS vector) LIMIT 5"; using var cmd = new NpgsqlCommand(querySql, conn); string embeddingString = $"[{string.Join(",", queryEmbedding.Select(v => v.ToString("G", CultureInfo.InvariantCulture)))}]"; cmd.Parameters.AddWithValue("queryEmbedding", embeddingString); return results.Any() ? results : new List<string> { "No relevant context found." }; }}
TextContext class:
public class TextContext{ public int Id { get; set; } public string Content { get; set; } = string.Empty; public float[] Embedding { get; set; } = [];}
Alternative: Using pgvector with Standard PostgreSQL (Without Neon)
You don't need Neon to run this setup. The TextRepository above works with any PostgreSQL instance that has the pgvector extension enabled. If you already have a local or self-hosted PostgreSQL database, you can use it directly.
Here's how to set it up:
1. Install the pgvector extension:
CREATE EXTENSION IF NOT EXISTS vector;
2. Create the table with a vector column:
CREATE TABLE text_contexts ( id SERIAL PRIMARY KEY, content TEXT NOT NULL, embedding vector(4096));
3. Update your connection string to point to your local/self-hosted PostgreSQL instance:
{ "ConnectionStrings": { "PostgreSQL": "Host=localhost;Port=5432;Database=rag_db;Username=postgres;Password=your_password" }}
Everything else - the TextRepository, RagService, and API endpoints - stays exactly the same. The code uses standard Npgsql with pgvector, so it's fully compatible with any PostgreSQL provider.
Neon gives you serverless scaling, instant provisioning, and zero database management, which is great for production workloads. But for local development, testing, or self-hosted scenarios, a standard PostgreSQL with pgvector works perfectly fine.
Implement a RAG Service
The RagService class is the core of the Retrieval-Augmented Generation (RAG) system, combining Neon’s serverless PostgreSQL for semantic search and Ollama’s AI model for response generation.
It retrieves relevant stored knowledge using vector similarity search, then uses an AI model (default: "mistral") to generate an answer strictly based on the retrieved context.
When a user asks a question, RagService:
- Queries the database via TextRepository, retrieving the top 5 most relevant records based on vector similarity.
- Combines the retrieved texts into a single context block.
- Ensures AI does not hallucinate by enforcing a strict prompt - if the answer isn’t in the provided context, it must respond with: "I don't know. No relevant data found."
- Sends the structured request to the Ollama API, instructing it to generate a response using only the given context.
- Returns a structured response, including both the retrieved context and the AI-generated answer.
public class RagService(TextRepository retriever, Uri ollamaUrl, string modelId = "mistral"){ private readonly TextRepository _textRepository = retriever; private readonly HttpClient _httpClient = new(); private readonly Uri _ollamaUrl = ollamaUrl; private readonly string _modelId = modelId; public async Task<object> GetAnswerAsync(string query) { // Retrieve multiple relevant texts List<string> contexts = await _textRepository.RetrieveRelevantText(query); // Combine multiple contexts into one string string combinedContext = string.Join("\n\n---\n\n", contexts); // If no relevant context is found, return a strict message if (contexts.Count == 1 && contexts[0] == "No relevant context found.") { return new { Context = "No relevant data found in the database.", Response = "I don't know." }; } var requestBody = new { model = _modelId, prompt = $""" You are a strict AI assistant. You MUST answer ONLY using the provided context. If the answer is not in the context, respond with "I don't know. No relevant data found." Context: {combinedContext} Question: {query} """, stream = false }; var response = await _httpClient.PostAsync( new Uri(_ollamaUrl, "/api/generate"), new StringContent(JsonSerializer.Serialize(requestBody), Encoding.UTF8, "application/json")); if (!response.IsSuccessStatusCode) { return new { Context = combinedContext, Response = "Error: Unable to generate response." }; } var responseJson = await response.Content.ReadAsStringAsync(); var serializationOptions = new JsonSerializerOptions { PropertyNameCaseInsensitive = true }; var completionResponse = JsonSerializer.Deserialize<OllamaCompletionResponse>(responseJson, serializationOptions); return new { Context = combinedContext, Response = completionResponse?.Response ?? "I don't know. No relevant data found." }; }}
Setup and Endpoints
The Program class initializes and runs a .NET Minimal API for a RAG system, combining Neon’s serverless PostgreSQL with Ollama’s AI model (mistral).
It sets up dependency injection, configuring an IEmbeddingGenerator to generate vector embeddings, a TextRepository to store and retrieve embeddings using pgvector, and a RagService to process AI-powered queries while ensuring responses are strictly based on stored knowledge.
The API provides two endpoints: POST /add-text, which generates embeddings and stores text for retrieval, and GET /ask, which retrieves the most relevant stored contexts, sends them to Ollama, and returns an AI-generated response only if relevant data is found.
public class Program{ public static void Main(string[] args) { var builder = WebApplication.CreateBuilder(args); var configuration = builder.Configuration; // Load settings from appsettings.json var connectionString = configuration.GetConnectionString("PostgreSQL"); if (string.IsNullOrEmpty(connectionString)) { throw new InvalidOperationException("Required configuration settings are missing."); } // Register services builder.Services.AddSingleton(sp => new OllamaEmbeddingGenerator(new Uri("http://127.0.0.1:11434"), "mistral")); builder.Services.AddSingleton(sp => new TextRepository(connectionString, sp.GetRequiredService<IEmbeddingGenerator>())); builder.Services.AddSingleton(sp => new RagService(sp.GetRequiredService<TextRepository>(), new Uri("http://127.0.0.1:11434"), "mistral")); var app = builder.Build(); // Minimal API endpoints app.MapPost("/add-text", async (TextRepository textRepository, HttpContext context) => { var request = await context.Request.ReadFromJsonAsync<AddTextRequest>(); if (string.IsNullOrWhiteSpace(request?.Content)) { return Results.BadRequest("Content is required."); } }); app.Run(); }}
For AI basics, also check out Semantic Search in .NET and ChatGPT API in C#.
Wrapping Up
In this post, we built a Retrieval-Augmented Generation (RAG) system in .NET, combining Neon’s serverless PostgreSQL for efficient vector storage and retrieval with Ollama’s AI model (mistral) for generating responses based on stored knowledge.
We structured the system to store text embeddings, perform semantic search using pgvector, and ensure that AI responses are strictly context-aware - eliminating hallucinations and improving reliability.
By leveraging Neon’s instant setup and automatic scaling, we eliminated database management overhead, while Ollama’s local inference allowed AI-powered responses without relying on external APIs.
This architecture enables fast, scalable, and intelligent knowledge retrieval, making it ideal for AI-powered chatbots, documentation assistants, and enterprise search solutions.
Next Steps?
You can extend this system by automatically syncing Confluence documentation, Notion database, or something else, adding user feedback loops, or optimizing vector search with hybrid retrieval techniques.
Whether you're building a developer assistant, a smart knowledge base, or an AI-powered search engine, this foundation sets you up for scalable and efficient AI-driven retrieval!
Check out the AI in .NET Starter Kit for the complete source code.
That's all from me today.
P.S. Follow me on YouTube.





