Sponsored
- Struggling with slow EF Core performance? Unlock up to 14x faster operations and cut execution time by 94% with high-performance library for EF Core. Seamlessly enhance your app with Bulk Insert, Update, Delete, and Merge—fully integrated into your existing EF Core workflows. Trusted by 5,000+ developers since 2014. Ready to boost your performance? Explore the solution
- Streamline your API development with Postman's REST Client a powerful tool for sending requests, inspecting responses, and debugging REST APIs with ease. Discover a more efficient way to build and test APIs at link.
Many thanks to the sponsors who make it possible for this newsletter to be free for readers.
Want to reach thousands of .NET developers? Sponsor TheCodeMan →
Background
If you are a beginner (seniors, wait a bit, there will be something for you too, and until then you can remind yourself) and you use EF Core, I strongly recommend you to go through this issue, and look at the code and benchmarks.
Before I talk about things you can do to improve EF performance, I want to note that these tips should be feature.
This is the way how you should write your queries.
So, there are many tips & tricks that I can show, but today I singled out these 4:
- Avoid query operations in loops
- Select only important columns
- Use the NoTracking method
- Use SplitQuery to separate queries
Let's get started.
1. Avoid query operations in loops
This is one of the first mistakes every junior faces.
When I started learning Entity Framework, I wrote code like this myself several times, until I realized that my application execution was really slow.
The main problem with this code is that it performs a query inside a loop, which leads to the N+1 query problem.
This happens because for each iteration of the loop, a new query is sent to the database, resulting in 100 individual queries, one for each entity with a specific Id.
Also, multiple database connections or resources can be consumed due to repeated queries, putting unnecessary load on the database.
public void QueryInsideLoop(){ using var context = new MyDbContext(); for (int i = 1; i <= 100; i++) { var entity = context.MyEntities.FirstOrDefault(e => e.Id == i); }}
To avoid performing query operations in a loop, you can cache the query results in memory and then operate on the data in memory, which can improve performance.
This method is suitable for collecting data with a small amount of data, otherwise the advantages outweigh the disadvantages.
public void QueryOutsideLoop(){ using var context = new MyDbContext(); var entities = context.MyEntities .Where(e => e.Id <= 100) .ToList(); foreach (var entity in entities) { var id = entity.Id; // Simulating loop logic }}
Benchmarks:
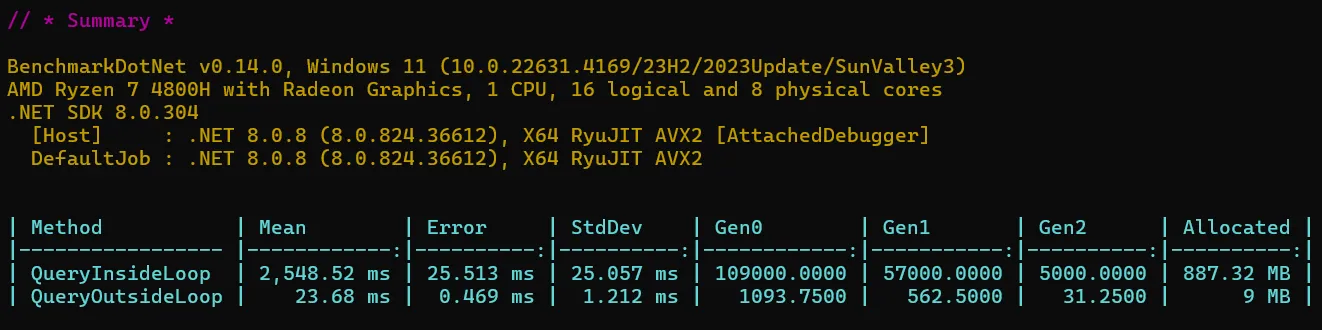
2. Select only important columns
If you don't need all 20 columns from the table, but Name, Surname and Year of birth, why would you extract the other columns?
That's right, it's not necessary.
Moreover, it is not recommended either because of performance or because of memory usage.
public void SelectAllColumns(){ using var context = new MyDbContext(); var results = context.MyEntities.ToList();}
To select only important columns and avoid loading unnecessary data, you can use projections with LINQ to select specific properties.
Instead of loading entire entities, you select only the columns you need. You can achieve this using anonymous types or a DTO (Data Transfer Object).
You only load the columns you need, reducing memory and bandwidth usage.
With fewer columns retrieved, the database query will be faster, especially with large datasets.
public void SelectImportantColumns(){ using var context = new MyDbContext(); var results = context.MyEntities.Select(e => new { e.Id, e.Name }).ToList();}
Benchmarks:
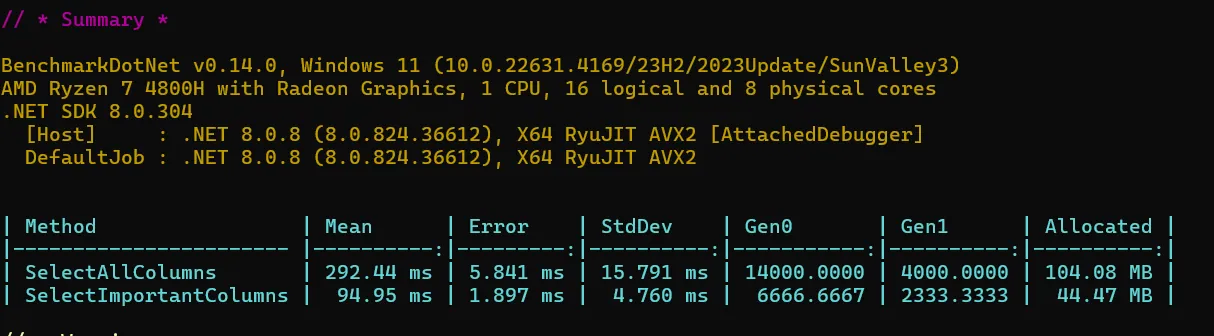
3. Use the NoTracking method
By default, Entity Framework tracks changes to the retrieved entities.
Tracking is useful when updating and deleting entity objects, but it incurs additional overhead when you only need to read the data.
public void SelectWithTracking(){ using var context = new MyDbContext(); var results = context.MyEntities.ToList();}
Use the NoTracking method to disable tracking, thereby improving performance. When AsNoTracking is used, Entity Framework doesn’t track changes to the retrieved entities, which reduces overhead and increases performance, especially for read-only data.
public void SelectWithNoTracking(){ using var context = new MyDbContext(); var results = context.MyEntities.AsNoTracking().ToList();}
Benchmarks:
![]()
4. Use SplitQuery to separate queries
By default, EF uses a single query to load both the main entity and its related entities, which can result in performance issues due to large join queries.
You will rarely need this feature, but it can help when you do.
It helps to avoid caretsian explosion problem. Let's look at an example:
public void DefaultSingleQuery(){ using var context = new MyDbContext(); var results = context.MyEntities .Include(e => e.RelatedEntities) .ToList();}
The SplitQuery option allows EF to execute separate queries for the main entity and its related entities, reducing the impact of large joins.
Using AsSplitQuery can increase performance and reduce complexity in such scenarios.
However, it also means multiple queries will be executed, so be sure to monitor the impact on database load.
public void UsingSplitQuery(){ using var context = new MyDbContext(); var results = context.MyEntities .Include(e => e.RelatedEntities) .AsSplitQuery() .ToList();}
Benchmarks:
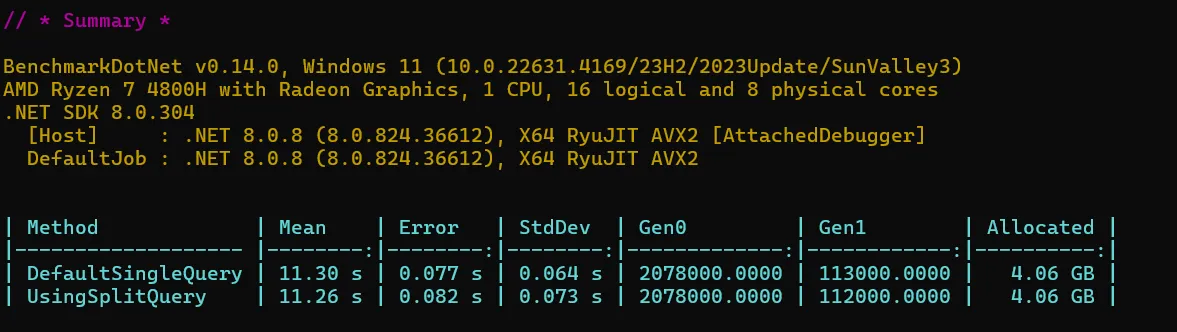
For more advanced EF Core optimizations, check out EF Core Compiled Queries and EF Core Interceptors.
Wrapping Up
There are many ways you can improve the performance of your queries.
Here I have shown 4 beginner ones, which I consider necessary (split query can be ignored).
The first thing I would always check is if I have queries in the loop - that's where the biggest performance improvements are hidden.
Also, don't return all the columns from the database because you almost never need them all.
If you do not need to track changes to the results, which is absolutely unnecessary in Read operations, the advice is to use the AsNoTracking() method.
That's all from me today.
Make a coffee and check the source code here.





